Abstract: There are several possible forms for a polynomial expression's terms, such as factored form, expanded form, Horner form, and many others. The set of such possible forms is an equivalence class of a universal algebra. However, when the operations are replaced with floating point pseudo-operations, the equivalence relation on the terms no longer holds and a rounding error is introduced. For each polynomial the computational effort and numerical error can be reduced with a form that is equivalent on the dense polynomial algebra by using a comparison of characteristic values. A local and a global theory of characteristic values is investigated to select the appropriate form on a given floating point interval.
The goal is to investigate a variety of characteristic criteria concerning the selection of optimal polynomial forms. In this paper, optimization criteria based on local and global characteristics will be investigated. In the past, it has been discussed that the Horner form of a polynomial is the optimal solution if only the number of operations is minimized Borodin (1971). Operation count is the only global characteristic which is currently used to identify the Horner form as optimal for general cases. Additional global characteristics will be introduced in this paper.
The local characteristics are based off of the locally compounded rounding errors from polynomial evaluation on a floating point pseudo-algebra, which has been pioneered by Wilkinson Wilkinson (1963). Several bounds for the error in the evaluation of the Horner form of a polynomial have been proved Muller (1981), Rump et al. (2015) and it has been shown that the Chebyshev form has worse error propagation characteristics than the Horner form Newbery (1974), Oliver (1979). There have also been some investigation of unified rounding error bounds for polynomial evaluation of forms in an arbitrary polynomial basis Barrio (2003). What has not been investigated yet is the error bound for any term of a universal algebra for polynomials, including arbitrary trees of operations that need not be in Horner form or basis form. This paper seeks to provide the theoretical terminology to express this error bound and to use it for a local and global characteristic analysis in polynomial form optimization.
A (universal) algebra Sapir (2014) for polynomials \(\mathbb{ P}\) is a set \(\mathbb{ K}\) with the closed operations \(\left\{ +,-,\times,/,\widehat{\ \ } \right\}\), with operations \(+,-,\times\) being mappings of the kind \(\mathbb{ K}^2\rightarrow\mathbb{ K}\) and \(/,\widehat{\ \ }\) being maps of the kind \(\mathbb{ K}\times\mathbb{ Z}\rightarrow\mathbb{ K}\). The algebra is denoted \(\mathbb{ P}(\mathbb{ K})=(\mathbb{ K},\left\{ +,-,\times,/,\widehat{\ \ } \right\})\). Examples are \(\mathbb{ P}(\mathbb{ F}_p),\mathbb{ P}(\mathbb{ Q}),\mathbb{ P}(\mathbb{ R})\), and \(\mathbb{ P}(\mathbb{ C})\).
Definition (Term). The composition of several basic operations of an algebra \((\mathbb{ K},O)\) is called a term. An abstract syntax tree of a polynomial term \(f\) is a directed rooted graph representing the functional structure of the expression. Let \(c(f)\) be the number of operations in \(f\)'s abstract syntax tree, let \(G(f)=\left\{ g_1,\dots,g_* \right\}\) be the set of constant scalars used in \(f\). Each vertex \(v_j(x,g_*,\dots,v_*)\in V(f)\) along the graph represents a function value recursively obtained from input leaves (scalar constants \(g_j\in G(f)\) or the variable \(x\)) or the result from nested vertices \(v_*\in V(f)\), thus \(c(f) = |V(f)|\). A term \(f\) is also a function on the set \(\mathbb{ K}\) and
\[ f = v_*(x,g_*,\dots,v_*(x,g_*,\dots,v_*(x,g_*,\dots),\dots,v_*(x,g_*,\dots)),\dots,v_*(x,g_*,\dots)),\\\left.\begin{aligned} x\in\mathbb{ K} \\ g_*\in G(f)\\ v_*\in V(f)\end{aligned}\right\rbrace \mapsto v_j.\] Definition. Let \(P(f)=\left\{ p_1,\dots,p_m \right\}\) be the set of all power exponents \(p_i\) in the polynomial expression \(f\) such that \(p_i\neq 0,1\), and let \(S(f)=\left\{ s_1,\dots,s_n \right\}\) be the set of all other coefficient scalars in \(f\).
The Horner form of a polynomial \(\mathcal{ H}(f)\equiv h_f(x,0)\) is defined as a recursive chain of vertices
\[ h_f(x,j) = \begin{cases} +(\times( h_f(x,j+1),x),s_j), & 0 \leq j < n \\ s_n, & j = n \end{cases},\]thus forming a nested alternating sequence of binary floating point operations. The expanded form and Horner form of a polynomial both use the same Epperson (2013) coefficients \(S(\mathcal{ E}(f))\equiv S(\mathcal{ H}(f))\), and are related by
\[ \mathcal{ H}(f) \equiv +(\times(+(...+(\times(+(\times(s_n,x),s_{n-1}),x),\dots),s_1),x),s_0) =\Sigma\left( \times(\widehat{\ \ }(x,j),s_j),j,1,n\right) \\ = +(\times(\widehat{\ \ }(x,0),s_0), \dots, \times(\widehat{\ \ }(x,j),s_j), \dots ,\times(\widehat{\ \ }(x,n),s_n) = \sum_{j=0}^ns_jx^j \equiv \mathcal{ E}(f) \]Note that \(P(\mathcal{ H}(f)) = \emptyset\) and \(P(\mathcal{ E}(f))\subset\left\{ 2,\dots,|S(\mathcal{ E}(f))|+1 \right\}\) for any polynomial \(f\).
Another possible form of \(f\) is guaranteed by the fundamental theorem of algebra, which tells us that any polynomial with complex coefficients has \(n\) roots \(r_j\in\mathbb{ C}\), where
\[ \mathcal{ F}(f) \equiv \prod_{j=1}^n (x-r_j) = \Pi(-(x,r_j),j,1,n) = \times(-(x,r_1),\dots,-(x,r_j),\dots,-(x,r_n)) \] Example. Consider an expression \(f\) such that \(\mathcal{ E}(f) = 4x^4-44x^3+61x^2+270x-525\). Then corresponding sets are \(S(\mathcal{ E}(f)) = \left\{ 4,-44,61,270,-525 \right\}\) and \(P(\mathcal{ E}(f)) = \left\{ 4,3,2 \right\}\), while the Horner form has \(P(\mathcal{ H}(f)) = \emptyset\). For the factorized form, \(P(f) = \left\{ 2_1,2_2 \right\}\) and \(S(f) = \left\{ -6,-21,2,-5 \right\}\). Figure below shows the different forms. Note that in this case, a fully factored form \(\mathcal{ F}(f)\) was not obtained, as it is inaccessible to the algorithm.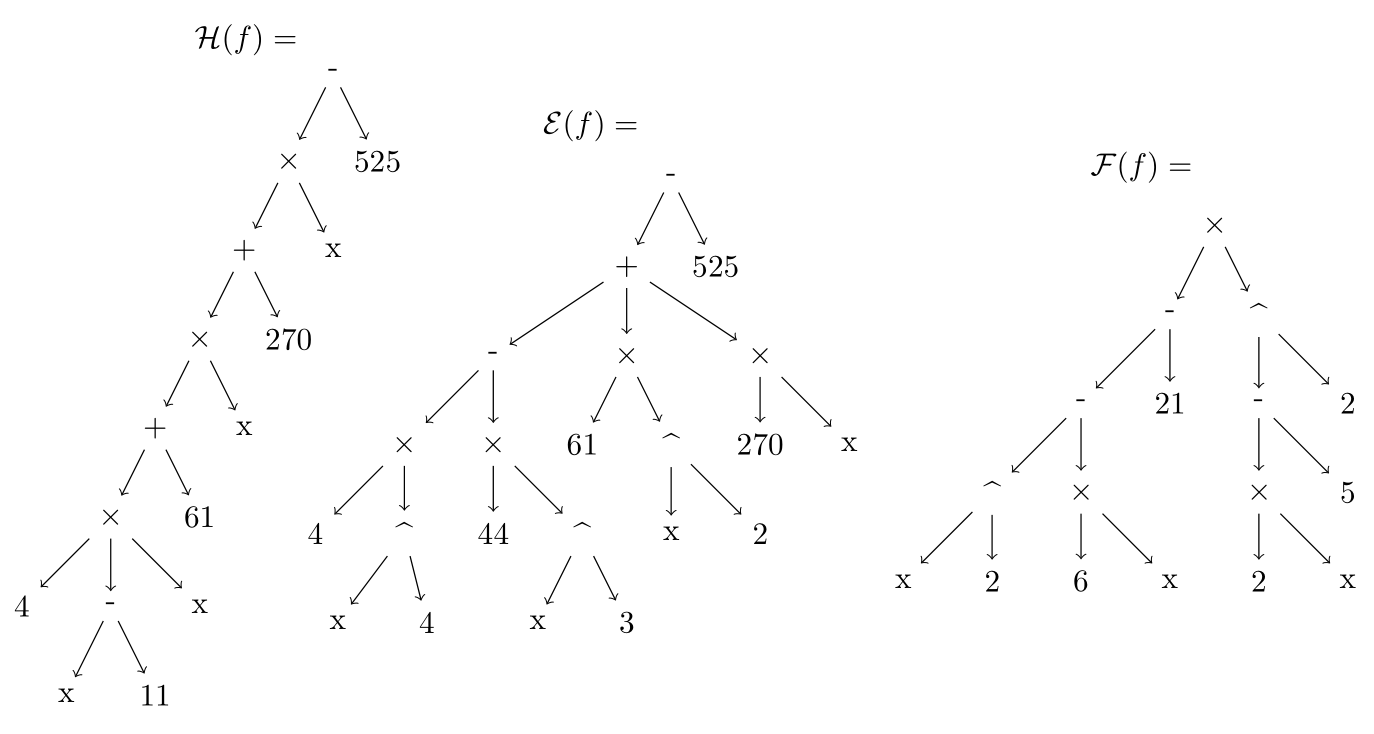
Figure. Abstract syntax trees of \(\mathcal{ H}(f),\mathcal{ E}(f),\mathcal{ F}(f)\) with vertices \(v_j\) and leaves \(x\) and \(g_*\).
Let \(a(x),b(x)\) be terms of a polynomial algebra \(\mathbb{ P}(\mathbb{ K})\). Define a relation \(\sim\) such that \(a\sim b\) if and only if \(a(x)=b(x)\) for all \(x\in\mathbb{ K}\). It is trivial to show that \(\sim\) is an equivalence relation on \(\mathbb{ P}(\mathbb{ K})\), so there exists a partition of \(\mathbb{ P}(\mathbb{ K})\) into \(\mathscr{ E}(f) := \left\{ a\in\mathbb{ P}(\mathbb{ K}):a\sim f \right\}\in\mathbb{ P}(\mathbb{ K})/\sim\) equivalence classes.
Thus it is clear that \(|\mathscr{ E}(f)|\geq3\) for any non-trivial polynomial for which these base forms do not coincide. In fact, \(|\mathscr{ E}(f)|=\infty\) since there are infinite possibilities of rearranging the same polynomial's terms using cancellations. We will restrict ourselves to the forms accessible via algorithmic rewriting and remark that there are practically inaccessible forms. For example, it is not always possible to compute the factorized form of a polynomial in terms of a closed form expression, since irrational roots are possible.
Recall that a floating point number is a value represented by a finte sequence of bits Higham (2002). Let \(n\) be the number of bits assigned to the fractional mantissa \(m\) and let \(r\) be the number of bits assigned to the exponent \(t\). Using a signed \(1+n+r\) bit representation, floating point numbers have the form \( x := \text{sgn}(x)\cdot m \cdot 2^{t-s} \). where \(\text{sgn}(x)\) is the sign of the number, \(m\) is the mantissa
\[m = \sum_{k\in B}2^{-k}\]with \(B\subseteq\left\{ 1,\dots,n \right\}\), and \(t\) is an integer such that \(0\leq t\leq 2^r-1\) with shift \(s := 2^{r-1}-1\). The set of bits (numbered from 1 to \(n\)) that are true in the mantissa is the set \(B\).
Definition (Floating point set). The set of all floating point numbers that can be represented with an \(n\)-bit mantissa with and an \(r\)-bit exponential shift of \(s=2^{r-1}-1\) is
\[ \mathbb{ M}(n,s) := \bigg\{x\in\mathbb{ Q}\,\bigg|\,x = \pm\sum_{k\in B} 2^{t-s-k},B\subseteq\left\{ 1,\dots,n \right\},t\in\left\{ 0,\dots,2s+1 \right\}\bigg\}\subset\mathbb{ Q}. \] Consider the 1 bit for \(\text{sgn}(x)\), \(n\) bits for the mantissa, and \(r\) bits for the exponent. Then it follows that \(0\leq t\leq 2s+1 = 2^r-1\) implies \(r = 1+\log_2(s+1)\) is the number of bits for the exponent. Hence, the number of bits per floating point number is \(2+n+\log_2(s+1)\). The IEEE-754 standard for single precision 32-bit floating point is \(\mathbb{ M}(23,127)\) and it is \(\mathbb{ M}(52,1023)\) for 64-bit double precision. For each bit there are two possibilities, therefore the size of a floating point set is \( |\mathbb{ M}(n,s)| =2^{1+n+r} = 2^{2+n+\log_2(s+1)} = 4(s+1) 2^n\), which is finite. The main numerical difficulty we will encounter can be attributed to the fact that
\[|\mathbb{ M}(n,s)|<|\mathbb{ Q}|<|\mathbb{ R}|.\]It turns out that \(\mathbb{ P}(\mathbb{ M}(n,s))\) is not a universal algebra, but rather must be considered a pseudo-algebra since the operations must be replaced with rounded pseudo-operations to be closed. Let \(x\in \mathbb{ M}(n,s)\subset\mathbb{ Q}\) and let \(a\equiv (1+x)\cdot x\) and \(b\equiv x+x^2\). The following steps apply to positive values of \(x\), but similar steps can be followed for a negative value. Specifically, let \(x = \sum_{k\in B} 2^{t-s-k}\) for some \(B\subset\left\{ 1,\dots,n \right\}\) such that \(t-s\notin B\) with \(0\leq t\leq s\). Then \(1+x = \sum_{k\in B\cup\left\{ t-s \right\}}2^{t-s-k}\) and \((1+x)\cdot x = \sum_{k\in\tilde B} 2^{t-s-k}\) for some \(\tilde B\). If \(\min B=1\), then \(2t-2s-2\in\tilde B\). Then, \(t-s-n>0\) implies that \(2t-2s-2>2(n-1)\). However, \(\max B\leq n\leq2(n-1)\) implies that \(2t-2s-2>\max B\). Thus, rounding must be introduced by taking \(\sum_{k\in\tilde B\cap\left\{ 1,\dots,n \right\}}2^{t-s-k}\) to approximate the nearest value of \((1+x)\cdot x\) in \(\mathbb{ M}(n,s)\). Likewise, for \(x+x^2\) it is possible for rounding to be introduced at each of the two operations (depending on \(B\)). Generally, the number and error of these roundings for the terms \(a\) and \(b\) need not be the same. Therefore, the resulting values of evaluating \(a(x)\) and \(b(x)\) need not be equal for all \(x\in\mathbb{ M}(n,s)\).
Consequently, the equivalence relation \(\sim\) does not hold for terms in \(\mathbb{ P}(\mathbb{ M}(n,s))\) which would otherwise be in the same equivalence class for \(\mathbb{ P}(\mathbb{ K})\) with a dense set \(\mathbb{ K}\).
This necessitates the introduction of the floating point error introduced by the rounding at each operation of the term of a polynomial algebra. The machine epsilon upper bound of the relative error due to floating point rounding is \(\epsilon:=2^{-n}\). Let \(\delta_j(x)\) be the the floating point round-off error at each operation \(v_j\) such that \(0\leq\delta_j(x)\leq\epsilon\) for all \(x,j\). The propagation of this error can be understood recursively by defining the term rewrite map \(alg:\mathbb{ P}(\mathbb{ K})\rightarrow\mathbb{ P}(\mathbb{ M}(n,s))\) as
\[ alg(v_j) := (1+\delta_j(x))\cdot v_j(x,g_*,alg(v_1),\dots,alg(v_{c(f)})). \]Define \(abs(f)\) to be the expression transformation that replaces all elements of \(s_i\in S(f)\) with \(|s_i|\), i.e. replace any non-exponent scalar with its modulus. Then \(abs:V(f)\rightarrow \mathbb{ P}(\mathbb{ K})\) is the term rewrite function
\[ abs(v_j) := \begin{cases} +_j(|x|,|g_*|,abs(v_1),\dots,abs(v_{c(f)})) & \text{if }v_j =\, - \\ \widehat{\,\,}\,_j(|x|,g_*,abs(v_1),\dots,abs(v_{c(f)})) & \text{if } v_j =\, \widehat{\ \ } \\ v_j(|x|,|g_*|,abs(v_1),\dots,abs(v_{c(f)})) & \text{if } v_j \in V(f)\backslash\left\{ -,\widehat{\ \ } \right\} \end{cases}. \]For example, \(abs(4x^4-44x^3+61x^2+270x-525) = 4x^4+44x^3+61x^2+270x+525\). Note that \(\left[ abs(f)\right](x)\) is the evaluation of this transformed expression at \(x\). For an expression based on a polynomial basis, it has been shown that the round-off error bound can be distributed over the operations and ultimately rearranged into expanded form Demmel (1997). By rearrangement, a bound on the round-off error can be estimated at each \(x\).
Theorem. The maximum floating point error for evaluating \(f=f(x)\) is bounded by
\[ \delta(f,x,\epsilon) = \epsilon\cdot c(f)\cdot \left[ \text{abs}(f)\right](x),\qquad \lim_{\epsilon\rightarrow0}\delta(f,x,\epsilon) = 0, \]with property \(\delta(f,x,\epsilon)>0\) for all \(x\in(0,\infty)\) and \(\epsilon>0\) for any non-trivial \(f\).
Proof. Take expanded form of \(alg(f)\), note that there are at most \(c(f)\) of \(1+\delta_k(x)\), hence
\[ \mathcal{ E}(alg(f)) \equiv \sum_{j=0}^n s_jx^j\prod_k(1+\delta_k(x)) \leq \sum_{j=0}^n s_j x^j (1+\epsilon)^{c(f)} \leq \sum_{j=0}^n s_jx^j(1+c(f)\cdot\epsilon), \\ \left| f-\mathcal{ E}(alg(f))\right| \leq \left| \sum_{j=0}^n s_j x^j(1+c(f)\cdot\epsilon)-\sum_{j=0}^ns_jx^j\right| \leq \left| \sum_{j=0}^n s_j x^j c(f)\cdot \epsilon\right| \leq \epsilon\cdot c(f)\sum_{j=0}^n|s_j|\,|x|^j. \]Observe that this is equivalent to \(\epsilon\cdot c(f)\cdot abs(\mathcal{ E}(f)) \leq \epsilon\cdot c(f)\cdot abs(f) = \delta(f,x,\epsilon)\). \(\square\)
For each polynomial form, the calculation of the bound will be different due to variations in \(c(f)\) and error propagation. The scaled error bound is \(\delta(f,x,\epsilon)/|x|\) and we denote \(\Omega(f,\epsilon)\) as the maximum floating point value of \(x\) before the evaluation for \(f\) reaches the floating point ceiling.
Figure. Graph of the scaled bound for the polynomial \(f\)
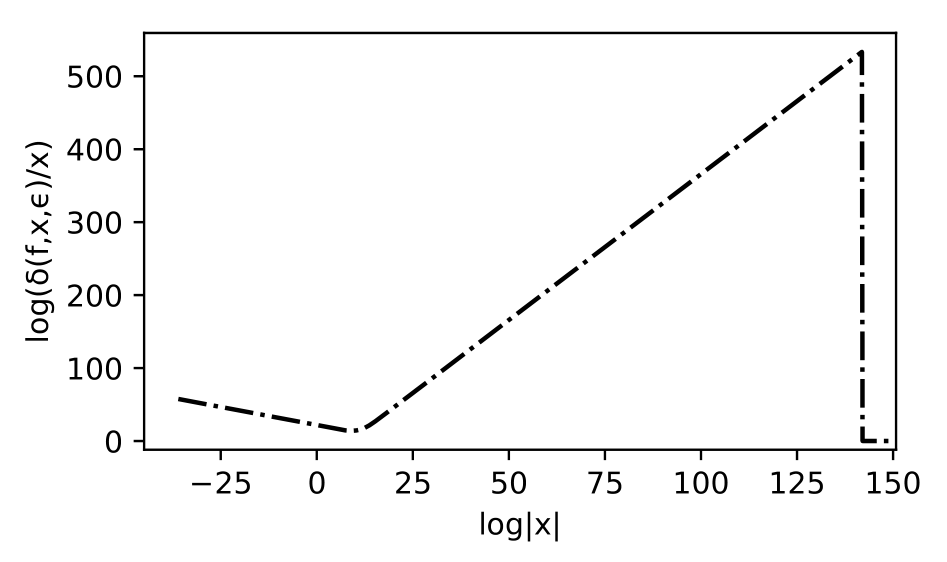
In order to obtain a normalized comparison of each bound the average of the Stieltjes integeral can be obtained. Then to measure the accumulation discrepancy \(\Xi\) over the floating point interval due to the pseudo-operations versus arbitrary precision computations, the integral
\[ E(f,\epsilon) = \int_{\epsilon>0}^{\Omega(f,\epsilon)} \log\left[ \frac{\delta(f,x,\epsilon)}{x}\right]\,d\log x, \quad \Omega(f,\epsilon) = \underset{x\in(0,\infty)}{\text{arg max}}\, \delta(f,x,\epsilon)\in\mathbb{ M}(n,s) \]is estimated with Simpson-Stieltjes integral Rudin (1976) using different expression forms \(f\in\mathbb{ P}(\mathbb{ M}(n,s))\). Given a partition
\[\mathcal{ P}(\Delta):0<\epsilon = x_0 < x_1 < \dots < x_{\eta(f,\epsilon)-1} < x_{\eta(f,\epsilon)} = \Omega(f,\epsilon)\]such that \(\log x_i-\log x_{i-1} \equiv \Delta\) is constant, the Simpson's rule Tveito et al. (2010) estimate for \(E(f,\epsilon)\) is
\[ E(f,\epsilon) \approx E(f,\epsilon,\Delta) = \frac{\log\left( \frac{\Omega(f,\epsilon)}{\epsilon}\right)}{6\eta(f,\epsilon)}\sum_{k=1}^{\eta(f,\epsilon)} \log\left[ 2^4\frac{\delta(f,x_{k-1},\epsilon)\cdot\delta(f,x_k,\epsilon)}{x_{k-1}(x_{k-1}+x_k)^4x_k} \cdot\delta\left( f,\frac{x_{k-1}+x_k}2,\epsilon\right)^4\right], \\ = \frac1{6\Delta}\log\left[ \frac{e^\Delta\Omega(f,\epsilon)\cdot\delta(f,\epsilon,\epsilon)}{\epsilon\cdot\delta\left( f,e^\Delta\Omega(f,\epsilon),\epsilon\right) } \prod_{k=1}^{\eta(f,\epsilon)} \delta\left( f,\frac{x_{k-1}+x_k}2,\epsilon\right)^4 \frac{2^4\delta(f,x_k,\epsilon)^2}{x_k^2(x_{k-1}+x_k)^4}\right] \]where
\[ \eta(f,\epsilon) = \log_{e^\Delta}\left( \frac{\Omega(f,\epsilon)}\epsilon\right) = \frac{\log\left( \Omega(f,\epsilon)\right)-\log\epsilon}{\log x_i-\log x_{i-1}}\in\mathbb{ N}, \qquad \forall i \leq \eta(f,\epsilon). \]Then \(E(f,\epsilon,\Delta)\rightarrow E(f,\epsilon)\) as \(\Delta\rightarrow0\). However, using finite precision floating point arithmetic and \(\epsilon,\Delta>0\), it follows that the values of \(E\) may differ for different forms of \(f\) when calculated numerically. Thus
\[ |\Xi(f,\epsilon,\Delta)| \equiv \left| E(\mathcal{ F}(f),\epsilon,\Delta) - E(\mathcal{ H}(f),\epsilon, \Delta)\right| \geq 0. \]Now, if \(\Xi(f,\epsilon,\Delta)>0\), we can know that \(\mathcal{ H}(f)\) has a lower floating point error bound than \(\mathcal{ F}(f)\) or vice versa. There are possible real-world cases where \(\Xi(f,\epsilon,\Delta)=0\), hence supplemental computational information may be used to characterize expression form desirability. Typically the memory allocation, timing, and operation function call count \(c(f)\) are a deciding factor, as will be discussed in the following section.
Due to the \(f,\epsilon\) dependence of \(\Omega(f,\epsilon)\), the integral is averaged and renormalized for comparison,
\[ \phi(f,\epsilon,\Delta):=\frac{E(f,\epsilon,\Delta)}{\left( \log\Omega(f,\epsilon)-\log\epsilon\right)^2}, \qquad \text{and} \qquad \Phi(f,\epsilon,\Delta) := \frac{\phi(f,\epsilon,\Delta)}{\phi(f,2^{-255},\Delta)}. \]That value makes comparison of the integrals over floating point intervals of varying precision easier. Specifically, \(\phi\) divides out and averages the error over the floating point interval, while \(\Phi\) converts the value into a dimensionless ratio with respect to an equivalent arbitrary precision computation.
One of the key pieces of information characterizing the error bound \(\delta(f,x,\epsilon)\) was the degree \(c(f)\) of the abstract syntax tree and the scaling by input of \(x\) exponents \(p_i\in P(f)\) and by scalars \(s_i\in S(f)\). Since the local round off error estimation based on the special values mentioned requires a significantly large number of steps to compute for a floating point interval, a new characteristic value method requiring much less computational effort is needed. These values can be mapped into a characteristic value by a composition of maps \(\mathbb{ P}(\mathbb{ K})\rightarrow \mathbb{ N}\times S(\mathbb{ P}(\mathbb{ K}))\times{P}(\mathbb{ P}(\mathbb{ K})) \rightarrow \mathbb{ R}\). The newly defined expression value \(\nu\) for a form \(f\) (available in the SyntaxTree.jl Reed (2018) package for Julia as SyntaxTree.exprval(expr)) is
which only depends on the input of \(f\in\mathbb{ P}(\mathbb{ K})\) and knowledge of \(P(f),S(f)\) and \(c(f)\in\mathbb{ N}\). This compuation requires no local or global evaluation of errors. Specifically, this formula is constructed as a product of three values, so each form can be thought of as having a position in a parameter space,
\[ \left( \sigma_{S(f)}\right)^2 := \overline{ s}^2 = \sum_{s\in S(f)}\frac{(\log|s|-\mu_{S(f)})^2}{|S(f)|-1}, \quad \mu_{P(f)} := \overline{ p} = \frac1{|P(f)|}\begin{cases} \displaystyle\sum_{p\in P(f)}|p|, & P(f)\neq\emptyset \\ 1.0, & P(f)=\emptyset \end{cases}. \]So the expression value \(\nu(f) \equiv c(f)\cdot \sqrt{|\mu_{S(f)}|\sigma_{S(f)}}\cdot \mu_{P(f)}\) is a statistical characteristic that maps the parameter space to a real number by taking the product of the operation count, average exponent, and geometric mean of the logarithmic scalars' mean and their standard deviation. This quantity helps quantify to what extent the operation values from the calculations experience roundoff error and memory consumption, as larger values correlate with increased memory consumption and possible error.
The goal is to choose a form \(g\in\mathscr{ E}(f)=\left\{ f,\mathcal{ F}(f),\mathcal{ H}(f),\dots \right\}\in\mathbb{ P}(\mathbb{ K})/\sim\) such that the expression value \(\nu(g)\) is as small as possible. Assuming existence, the preferred optimal expression form \(o(f)\) is defined as
\[ o(f) := \underset{g\in\mathscr{ E}(f)}{\text{arg min}}\, \nu(g). \]Optimization of the \(\nu\) metric enables selection of the expression form of \(f\) that has optimal balance of coefficient size, computational complexity, floating point accumulation error, and least exponential powers.
Using automated testing Reed (2018) of different polynomial forms with randomized coefficients or roots, the optimal expression forms are determined. The methods used include a Simpson-Stieltjes integral method to estimate error bound discrepancy and a computationally efficient characteristic method.
The Julia language is especially suited for the task carrying out the numerical experiments due to the reflexivity of the language and subsequent code generation. Native support in the language for various floating point formats as well as arbitrary precision floating point support help make the computation straight forward. The SyntaxTree.exprval method can be used to select optimal numerical code for polynomial basis functions with the Reduce.jl Reed (2017) symbolic rewrite package for the Julia language developed by the author, which is based on high-level code generation and macros operating on abstract syntax trees.
Figure. Bound comparisons for forms of polynomials show greater accuracy near roots
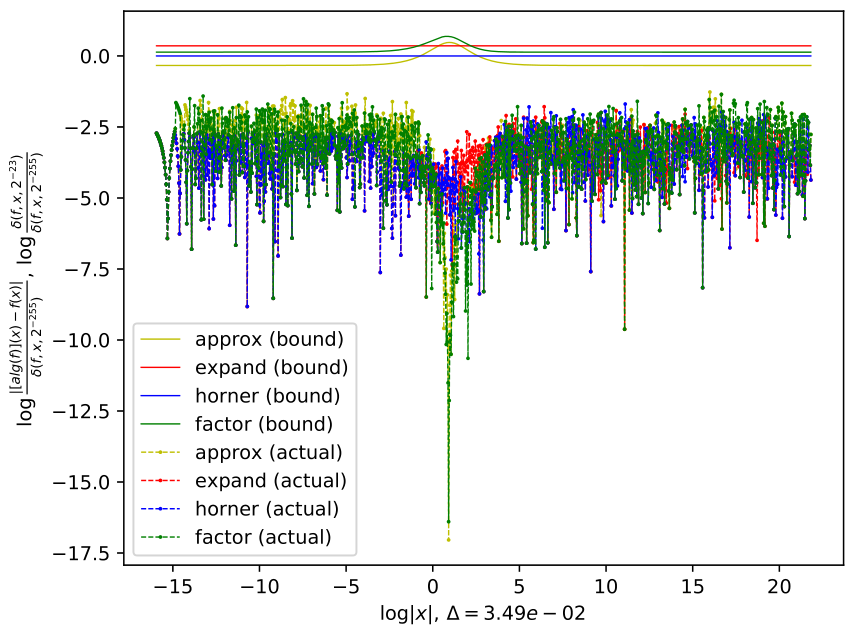
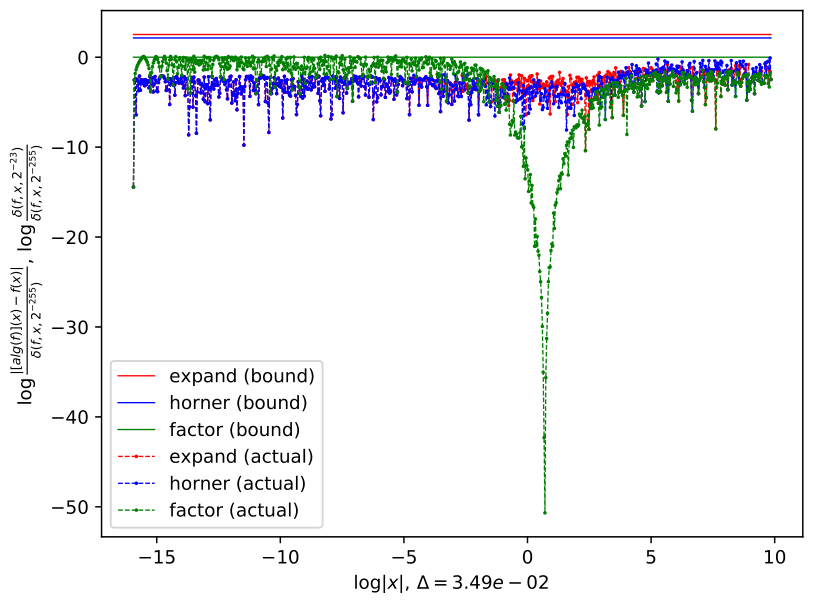
An analysis of the actual error bounds shown in Figure 3 indicates that the predicted theoretical bounds do contain the true error values. While this bound is equivalent to an optimistic bound for Horner's form, the bound can still be improved for factored form near roots. Observe that in Figure 3 the true error is less near the roots, while the predicted bound for factored form has a bump at the same location. Also observe that some polynomials are piecewise optimal with Horner form best in one interval and factor form better on a different region of the interval. In a follow up paper, a more detailed local analysis of the error bound for factored form will be provided in comparison with the bound proved in this paper, where the bounds near roots of factored form terms will be investigated.
Example. Consider the expression \(f\) from figure 3(a). The appropriate form is \(\mathcal{ H}(f)\).\[\begin{array}{c|cccc} & \mathcal{ E}(f) & \mathcal{ H}(f) & \mathcal{ F}(f) & \mathcal{ R}(f) \\ (c,\sigma,\overline{ s},\overline{ p}) & (10, 2.228, 4.228, 3.0) & (7, 1.687, 3.951, 1.0) & (8, 0.861, 1.785, 2.0) & (5, 0.595, 1.337, 2.0) \\ \nu(f) & 92.0863245436194 & 18.073187517116104 & 19.83687735202171 & 8.923106875013321 \\ \Phi(f,\epsilon,\Delta) & 1.029960829726364 & 0.9999999667868625 & 1.0148546060152759 & 0.9778483323687441 \\ \text{bytes} & 3014.7186666666666 & 185.24666666666667 & 156.549 & 173.35433333333333 \end{array}. \] Example. Consider the expression \(f\) from figure 3(b). The appropriate form is \(\mathcal{ F}(f)\).
\[\begin{array}{c|cccc} & \mathcal{ E}(f) & \mathcal{ H}(f) & \mathcal{ F}(f) \\ (c,\sigma,\overline{ s},\overline{ p}) & (25, 3.212, 6.810, 5.5) & (17, 1.340, 6.810, 1.0) & (2, 1.504, 0.693, 9.0) \\ \nu(f) & 643.1128014851948 & 51.3441179785937 & 18.378934415299785 \\ \Phi(f,\epsilon,\Delta) & 1.2735710938627083 & 1.2317985884634024 & 1.0000000140002385 \\ \text{bytes} & 3135.4363333333336 & 240.71133333333333 & 98.13 \end{array}. \]
The source code that generated the results in this paper can be obtained from Wilkinson.jl Reed (2018) package along with the source for the paper, which will be distributed using the VerTeX.jl format.
using Reduce, Wilkinson; import SyntaxTree: exprval
PolynomialComparison(polyexpand(:x,[-525,270,61,-44,4]))
PolynomialComparison(polyfactors(:x,2ones(9)))
PolynomialComparison(:(x^9-2))
PolynomialComparison(polyfactors(:x,[23029832,2039822,923,1]))
PolynomialComparison(Algebra.prod(:((x+n)^n),:n,1,5))
PolynomialComparison(:((((x - 1) ^ 2 * x ^ 2 - 1) ^ 2 - 1) ^ 2))Evaluating PolynomialComparison objects computes the listed data, which can be displayed with plot using the PyPlot.jl package by default. Note that all the global characteristic values are the optimal when minimized (for \(\nu,\Phi\), memory allocation, etc.). Typically, the expanded form requires significantly more memory consumption, while the factored and Horner form are the most competitive. Sometimes, the rounded roots form does very well also, but the numerical error depends on the accuracy of the roots used.
\[\begin{array}{c|cccc} & \mathcal{ E}(f) & \mathcal{ H}(f) & \mathcal{ R}(f) \\ (c,\sigma,\overline{ s},\overline{ p}) & (2, 1.504, 0.693, 9.0) & (2, 1.504, 0.693, 9.0) & (24, 0.481, -0.446, 1.0) \\ \nu(f) & 18.378934415299785 & 18.378934415299785 & 11.11841280417285 \\ \Phi(f,\epsilon,\Delta) & 1.000000041184039 & 1.000000041184039 & 1.5646134826064557 \\ \text{bytes} & 2931.4513333333334 & 97.98633333333333 & 1948.7503333333334 \end{array}. \] Example. Consider the expression \((x - 1)(x - 923)(x - 2039822)(x - 23029832)\), appropriate form is \(\mathcal{ F}(f)\).
\[\begin{array}{c|cccc} & \mathcal{ E}(f) & \mathcal{ H}(f) & \mathcal{ F}(f) \\ (c,\sigma,\overline{ s},\overline{ p}) & (10, 18.39, 31.28, 3.0) & (7, 7.091, 31.28, 1.0) & (5, 6.679, 9.827, 1.0) \\ \nu(f) & 719.5002771106713 & 104.26001750963377 & 40.50789575171883 \\ \Phi(f,\epsilon,\Delta) & 1.0218699473050092 & 1.0106162581578118 & 0.9999999990283254 \\ \text{bytes} & 3002.5823333333333 & 147.319 & 142.482 \end{array}. \]
Example. Consider the expression \(\displaystyle\prod_{n=1}^7 (x+n)^n\). The appropriate form is \(\mathcal{ F}(f)\).
\[\begin{array}{c|cccc} & \mathcal{ E}(f) & \mathcal{ H}(f) & \mathcal{ F}(f) \\ (c,\sigma,\overline{ s},\overline{ p}) & (55, 19.81, 28.78, 15.0) & (55, 6.867, 28.78, 1.0) & (14, 0.558, 1.3607, 4.5) \\ \nu(f) & 19699.29024455475 & 773.2300130297801 & 54.944165783862005 \\ \Phi(f,\epsilon,\Delta) & 1.0096353233930733 & 1.0096353233930733 & 1.0 \\ \text{bytes} & 6451.475333333334 & 600.759 & 378.9683333333333 \end{array}. \] Example. Consider the expression \((((x-2)^2x^2-1)^2-1^2)\). The appropriate form is \(\mathcal{ F}(f)\).
\[\begin{array}{c|ccccc} & \mathcal{ E}(f) & \mathcal{ H}(f) & \mathcal{ F}(f) & \mathcal{ R}(f) & \mathcal{ O}(f) \\ (c,\sigma,\overline{ s},\overline{ p}) & (35, 1.0, 3.1, 6.75) & (25, 0.7, 3.1, 4.0) & (12, 0.4, 0.7, 3.1) & (15, 0.5, 0.09, 2.0) & (8, 0.7, 1.0, 2.0) \\ \nu(f) & 427.8418916234 & 152.3413216001 & 21.59664312746 & 6.93957471367 & 13.3341854087 \\ \Phi(f,\epsilon,\Delta) & -4.3314048550 & -4.41216949054 & -4.58108950145 & 1.035101808575 & 0.999999969189 \\ \text{bytes} & 3455.111 & 287.113666667 & 178.6336666667 & 1484.140333333 & 129.7606666668 \end{array}. \]
Remark. Occasionally the \(\Phi\) value is negative, which might seem surprising but this value is fully consistent with the theoretical and local true error bound data, the behavior of which will be discussed and explored in greater detail in the follow up paper.
The numerical data provided in the examples should help clarify why the expression value formula is defined the way it is. Observe that for expanded form, the operation count is typically very high along with the average exponent, while these values are smaller in Horner form. If the term can be factorized with real roots (exact or approximated) then expression value may be improved further. The factor algorithm provided by Reduce.jl does not automatically round the roots and hence can only provide a semi-factored form in some scenarios, as in Example 2. In these cases, the Horner form is more appropriate.
When a randomized polynomial is constructed, it is procedurally generated using its form's recursive abstract syntax tree constructor. For forms like factorized and Horner, and some others, it is typically found that the particular randomized term is most optimal in the same form it was "generated in," since the form is simplest. By studying the characteristics of each method, a more efficient construct of code generation can be applied to numerical basis polynomials. Results indicate \(\nu(\mathcal{ H}(f)) \leq \nu(\mathcal{ F}(f))\) if and only if \(\Xi(f,\epsilon,\Delta)\geq0\) with a 100.0% agreement rate, implying that the simpler method is able to succesfully select for the optimal polynomial form to minimize error propagation measured in the more cumbersome integration. Based on the results from the analysis, the recommended algorithm for selecting the optimal form is:
e -> (h=horner(e); f=factor(h); exprval(h)[1] <= exprval(f)[1] ? h : f)Due to the computational simplicity of the expression value method in comparison to the floating point error bound Simpson-Stieltjes integral estimation method, the expression value method is the demonstrably faster, more efficient, and equally reliable method for determining the optimal expression form characterization.
A. B. Borodin, Horner's rule is uniquely optimal, Theory of machines and computations 1971.
J. H. Wilkinson, Rounding Errors in Algebraic Processes, 1963.
K. H. Muller, Rounding error analysis of Horner's scheme, Computing 1982.
S. M. Rump, F. Bunger, C.-P. Jeannerod, Improved error bounds for floating-point products and Horner's scheme, BIT Numer Math 2015.
A. C. R. Newbery, Error analysis for polynomial evaluation, Mathematics of Computation 1974.
J. Oliver, Rounding error propagation in polynomial evaluation schemes, Journal of Computational and Applied Mathematics 1979.
R. Barrio, A unified rounding error bound for polynomial evaluations, Advances in Computational and Applied Mathematics 2003.
M. V. Sapir, Combinatorial Algebra: Syntax and Semantics, 2014.
J. F. Epperson, An Introduction fo Numerical Methods and Analysis, 2013.
N. J. Higham, Accuracy and Stability of Numerical Algorithms, 2002.
A. Tveito, H. Langtangen, B. Nielsen, X. Cai, Elements of Scientific Computing, 2010.
M. Reed, SyntaxTree.jl, https://github.com/chakravala/SyntaxTree.jl 2018.
M. Reed, Wilkinson.jl, https://github.com/chakravala/Wilkinson.jl 2018.
M. Reed, Reduce.jl, https://github.com/chakravala/Reduce.jl 2017.
M. Reed, Differential geometric algebra using Leibniz, Grassmann, Proceedings of JuliaCon 2019.

